데이터 마이닝 분석 방법
-그 중 하나가 군집 분석
-같은 그룹 내의 객체들은 유사한 객체들로, 서로 다른 그룹의 객체와는 다른 특성을 가지도록 객체들의 그룹을 찾는 방법
-비지도적 학습적 분류기법
대부분의 방법은 지도적 학습
–>투표 결과를 바탕으로 나누는 것.
답을 알고있는 것을 바탕으로 시작하는 것.
반면 비지도 학습은 결과값을 모르는 애들을 대상으로 분류하는 것.
선거 전에 분석할 때!
군집의 수가 정의되지 않음
몇개로 분류하는 게 좋은건지 구분이 없다.
각 군집의 의미가 미리 정의되지 않음
–> 모호하지만 결과값을 모르면서 추출할 수 있다는 점에서 인기를 끌고있음
타 분석 알고리즘을 적용하기 위한 데이터 전처리로서 활용 가능
t1, t2 등의 투플을 하나의 클러스터 Kj로 분류함.
결국 클러스터는 함수로 정의됨.
투플 데이터를 각각의 클러스터로 매핑한다고 표현한다.
투플들의 집합인 클러스터가 곧 함수의 반환값이다.
지도학습의 경우
결과가 있는 데이터 바탕으로 분류함수 F(X) 찾는 것을 목표로 한다.

관측값이 없을 경우 지도학습을 쓸 수 없다.
활용 분야
패턴 인식
공간데이터 분석
이미지 프로세싱
마케팅
Land use
Well-Separated
Center-based
-경계선 문제가 생길 수 있음
Contiguous cluster
Density based
shared property
클러스터링 기법의 특징
많은 수의 데이터 대상으로 하고
arbitrary shape

q가 2이면 유클리드 방식의 거리 구하기이다.
주요 군집 분석 기법들
1.
분할 기반 알고리즘
N개의 객체가 포함된 데이터베이스 D를 대상으로 k개의 군집으로 분할 수행
여러개의 k를 생각하고 돌린 다음에 가장 맞는 아이를 고른다.
2.
K-means
주어진 k로 k-means 알고리즘은 4단계 수행
더이상 중심에 변화 같을 때
K-means 군집 평가
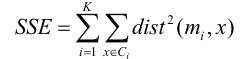
값이 작을수록 좋은 군집이다.
작은 k에서의 좋은 분석 결과는 높은 k에서의 나쁜 분석 결과보다 낮은 SSE를 가짐
장점: 속도 local optimum
단점: 값을 구할 수 있는 경우에만 적용 가능
계층 기반 클러스터링