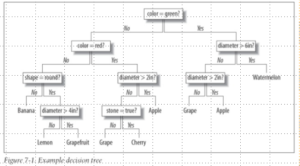
100개를 분류한다고 해보자
A: 50, B: 50
특정 노드에 특정 샘플(A 30개 B 0개)만 있으면 불순도 0
불순도가 적은 방향으로 트리를 확대시켜 나가자
가장 기본적인 알고리즘이 CART와 ID3
ID3
조건을 선택하는 게 아니라 컬럼을 선택한다.
예를 들어 x2라는 특성을 범위를 나눠서 결정
CART
우리가 지금까지 했던 것들
전처리가 많이 필요없다.
과적합
학습데이터에 너무 지나치게 맞추다 보면 일반화 성능이 떨어지는 모델을 얻게되는 현상
의사결정트리는 특히 이런 문제가 일어날 확률이 높음
Scikit-Learn에서의 의사결정트리
여러가지 옵션이 있다.
너무 depth가 커지면 오버피팅이 될 수 있기 때문에 max depth 정해줄 수도 있다.
끝에 있는 노드의 최소 샘플 수도 정할 수 있다. 마찬가지로 오버피팅을 방지하기 위한 파라미터들
max-features: 얘 역시 지금 train set에만 몰입되지 않도록 해줌

결정트리는 overfir되는 경향이 많아서 차라리 랜덤 포레스트, 부스팅 등 결정트리 기반의 보완된 알고리즘을 사용한다.
최적의 파라미터
정답이 없기 때문에 할 때마다 최적화를 해줘야 한다.
계속 반복문을 돌려서 찾아야 할까 (많이 쓰긴 한다)
대신 다른 방법이 존재한다
그리트 서치 : 관심있는 모든 파라미터의 조합 실행해보는 것.
컴퓨팅 파워가 많이 필요할 것.
과적합 방지
-학습 데이터의 일부를 따로 떼서 검증용으로 사용하는 기법
-교차 검증:
k-fold cross validation
i.e. 다섯 개로 쪼개서 하나씩 test해본다.
문제 해결을 위해 계층별 k겹 교차검증 가능
에러의 종류
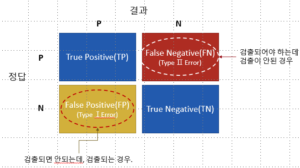
암 진단에서는 False Negative가 훨씬 중요한 에러
예를 들어 질병에 걸렸는데 음성 반응이 나오면 안 되기 때문에!
–> 정확도만으로 판단하는 데는 한계가 있다.
정밀도와 재현율을 같이 사용해야 한다.
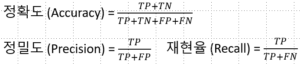
암 모델에서는 재현율이 중요해질 것
둘 다 중요할 때는 F1-score을 보자