Decision Tree가 많아져서 random forest
Decision Tree
node, edge, tips
easy to interpret
강력함.
entropy
high entropy –> mixed
어떤 데이터는 잘 섞여있을 것이다. 이를 우리가 decision tree를 이용해서 섞이지 않은 분리된 상태로 만든다.
노드 하나씩 거쳐갔을 때마다 entropy가 낮아진다.
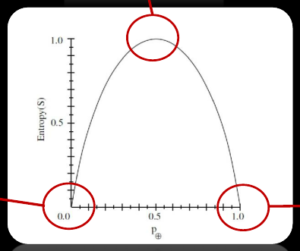
얼마나 entropy가 감소했는가
information gain = entropy(before) – entropy(after)
information gain 이 제일 높은 애를 최상위 노드로 한다.
![]()
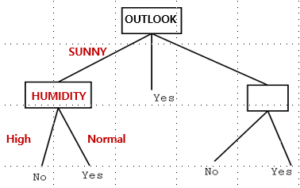
OUTLOOK으로 제일 위에 노드로 결정이 됐으므로
그 다음에는 SUNNY에 대해서
똑같이 진행한다.
![]()
Tip에 닿으면 엔트로피가 0이 된다!
Overfitting
이라는 문제 발생 가능
해결방법: prunning –> 너무 복잡한 트리가 되지 않도록 자른다.
랜덤포레스트의 경우 더 발전해서 트리를 자르지 않아도 되도록 한다.
i.e. 테니스의 여러 attribute 예를 들어 day, humidity, outlook, tennis 칠지 안 칠지
(과거 데이터) Day1, day2의 데이터를 알고있다.
overfitting은 다른 attribute를 쓰지 않고 day만으로 day3의 테ㅣ스 칠지 안 칠지를 결정하는 것.
c.f. 오버피팅의 경우 딥러닝에서는 생기지 않는다. 왜냐하면 워낙 큰 데이터를 갖고있어서 그 데이터 자체를 whole population이라 생각할 수 있기 때문
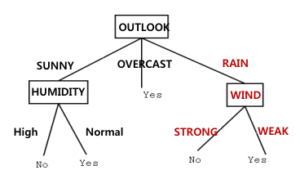
temperature는 여기서는 선택이 안 됨.
정리하자면
decision tree는
1. 해석이 쉽고
2. overfitting –> 잘라야 한다.
3. regression tree:
Y x1, x2, x3
x1가 0 ~ 100 이면 50으로 잘라서 달라지는 Y1과 Y2의 평균값이 크게 달라질수록 잘 자른 것.
–> accuracy가 높지는 않지만 쉽고 해석하기가 쉽다.
Random Forests
딥러닝 이전에 핫했던 방법론.
트리의 limitation:
low prediction accuract/high variance
ensemble을 하면 accuracy가 높아지더라
Bootstrap Aggregation
–> 분산이 적어진다.
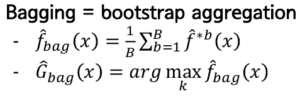
N을 조그마한 n개씩 B개로 쪼개서 각각에 평균을 낸 다음 요 아이들을 평균을 낸다!
Out of Bag
N에서 large N을 복원 추출한다.
large N으로 뽑아도 66%정도만 샘플로 쓰이게 된다.
그렇다면 나머지 33%는…?
66프로는 bag에 들어왔다
나머지는 out of bag (OOB)
※overfitting을 피하는 방법들
1.
그냥 데이터 나눠버리기 (Split) –> 구식 방법
-예를 들어 6:4로 나눠서 6으로 알고리즘 짜서 4로 테스트해봐라
-내 데이터에 너무 집중해서 생긴 문제이기 때문에 내 데이터를 일부 버리고 나머지로 하자
–> accuracy는 떨어지지만 나머지 데이터 셋으로 테스트를 해볼 수 있음
2.
Cross validation –> 좀더 머리씀
-나누는 작업을 여러번 반복함.
-예를 들어 9:1로 여러번 잘라서 하기 .
3.
OOB 테스트를 하겠다
-각각의 OOB를 바탕으로 에러테스트를 한다.
-오버피팅을 방지하면서 bagging의 장점까지 가져올 수 있다.

2nd) drop out
i.e. 미생물 6000종 –영향–> 피부노화도
6000개를 다 활용해버리면 n이 별로 없다
6000개 중에서 몇 개를 랜덤하게 날린 후에 피팅시킨다 (drop out)
오히려 더 variance가 크지 않은 결과를 만들 수 있다.
배깅하고 나서 각각의 경우 tip까지 다 피팅한다.
각각 나온 결과물을 aggregation을 할 때
classification의 경우 f(x1, x2, x3…xp) = 몇
예를 들어 얘가 0.5 이상이면 1로 하겠다.
그러면 B개에 대해서 0 혹은 1이 있을 것.
여기서 1 나온 비율이 0.5 이상이면 1이 될 것.
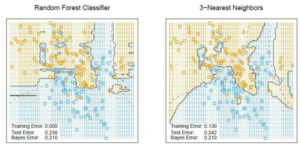
3-nearest neighbors
2차원 데이터에서 (x,y축은 attribute) 점점 원을 넓혀서 3개가 들어갔을 때 이 세개 점의 x 평균, y 평균을 구한다.
얘도 보면 알겠지만 overfit된 데이터가 나오는 것으로 알려져 있음.
베이지 에러: 어쩔 수 없이 통계적으로 나오는 오류
–> random forest가 더 우월하다.